Most teams building AI products make the same quiet mistake. They pick a model, run a demo, get stakeholder approval, and then when it comes to measuring whether the thing actually performs they grab whatever metric is easiest to explain in a slide. Usually accuracy. Sometimes nothing at all.
That is not an engineering problem. It is a product success measurement problem. Because the metric you pick is not just how you measure quality. It is how you define what quality means. Get it wrong and your team spends months optimizing toward an outcome nobody actually wanted.
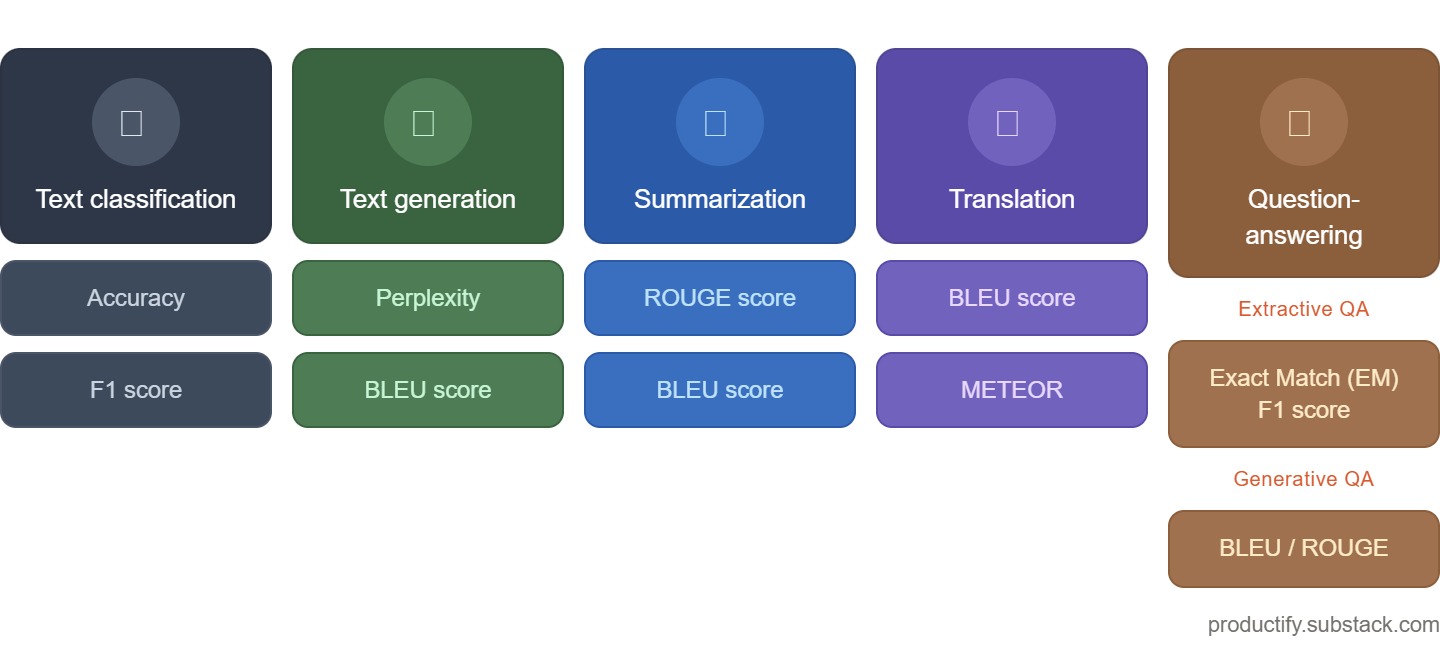
Here is the framework. Five NLP (Natural Language Programming) task types, seven metrics, and exactly when each one belongs in your product.
This edition is brought to you by Cuey. Get 2 months of Pro edition with link below!
AI is brilliant for first drafts. Not for product decisions. Cuey is a free Chrome extension that cross-checks ChatGPT, Claude, and Gemini in one tab. Catch hallucinations before they shape your next product decision.
Try Cuey free on Chrome and claim 2 months of Pro with code PRODUCTIFY
What NLP Is and Why It Shows Up Everywhere
NLP stands for Natural Language Processing, the part of AI that works with text and language. It is how machines read a contract, classify a transaction, translate a complaint, summarize a meeting, or answer a compliance question. If your product touches text in any way, you are in NLP territory whether you call it that or not.
The reason metrics matter more here than in most AI domains: language is ambiguous, context-dependent, and impossible to evaluate by eye at scale. You need a number that tells you, reliably, whether the model is doing what you built it to do. And that number changes depending on the task.
The Metric That Lets Fraud Slip Through
Accuracy sounds airtight. Of all the predictions the model made, what percentage were correct? It is the first metric every team reaches for. It is also the one that will let your fraud model declare victory while missing every actual fraud case.
Here is why. Say 97% of transactions on your platform are legitimate. A model that labels everything “not fraud” hits 97% accuracy without catching a single fraudulent transaction. The number looks great. The feature is useless.
F1 score is the fix. It forces you to balance two questions simultaneously: when the model flags something as fraud, how often is it actually fraud (precision)? And of all the real fraud cases in the dataset, how many did the model actually catch (recall)?
Take a small example.
Five transactions, ground truth is Fraud, Legit, Fraud, Legit, Fraud.
The model predicts Fraud, Fraud, Fraud, Legit, Legit.
Accuracy is 60%.
But the model caught 2 of 3 real fraud cases and threw one false alarm. Precision is 0.67, recall is 0.67, F1 is 0.67.
That number tells you something actionable. The 60% accuracy tells you almost nothing.
In any fintech context — fraud, credit risk signals, document classification, KYC intent detection — class imbalance is the default. F1 is not optional.
The Only Metric With No Reference
Every metric in this framework compares the model’s output against a human reference — except one.
Perplexity measures how surprised the model is by its own output. It is not asking “did the model say the right thing?” It is asking “did the model say something coherent at all?” A model that produces fluent, contextually predictable text has low perplexity — typically in the range of 2 to 20. A model generating word salad could score 300 or higher.
Two outputs, same prompt. “Your refund has been processed and will appear within 3 business days.” Versus “Refund your processed 3 days business the will.” The first is fluent. The second is broken. Perplexity tells them apart without needing a human to label them.
The trap is assuming fluency equals correctness. A model can produce beautifully coherent text that is factually wrong. Perplexity catches the incoherent failures. It does not catch the confident hallucinations. Use it during model selection, not as your production health metric.
BLEU Asks the Wrong Question for Summarization
BLEU score — Bilingual Evaluation Understudy — was built for translation. It measures precision: of all the words and phrases the model produced, what fraction appear in the human reference? Think of it as asking “did the model say the right words?”
A translation example. Reference: “The payment was not processed due to a technical error.” Model output: “The payment was not completed because of a technical issue.” BLEU checks word-by-word. “Completed” does not exactly match “processed.” “Issue” does not exactly match “error.” BLEU penalizes both even though a human reader would consider this a perfectly good translation. Score lands around 0.45 to 0.55 — punished for synonyms.
That limitation matters enormously when you try to use BLEU for summarization, which many teams do. BLEU only checks what the model said. It has no interest in what the model dropped. For a summarizer, what the model drops is the entire point of the evaluation.
Reference summary: “Applicant has stable income, a credit score of 720, and one prior default resolved in 2019.” Model summary: “The applicant earns a stable income and has a 720 credit score.” BLEU would score this reasonably. The words that appear are mostly correct. But the model deleted the prior default — the single most material piece of information for an underwriter. BLEU never noticed.
That is why summarization uses ROUGE — Recall-Oriented Understudy for Gisting Evaluation. ROUGE reverses the question. Instead of asking “did the model produce the right words?”, it asks “how much of the reference survived in the model’s output?” It catches deletions. BLEU does not. ROUGE-L, which finds the longest common subsequence between reference and prediction, is the most robust variant for production summarization pipelines because it handles paraphrasing without demanding exact word matches.
The rule: use BLEU when the risk is the model saying wrong things. Use ROUGE when the risk is the model leaving out the right things.
The Translation Metric That Actually Thinks
BLEU has been the benchmark standard for translation for two decades. It is fast, reproducible, and quoted on every model leaderboard. It is also bad at recognizing when a translation is correct but uses different words.
METEOR — Metric for Evaluation of Translation with Explicit ORdering — fixes this with three additions. It recognizes synonyms. It matches different forms of the same word through stemming. And it penalizes poor word order more intelligently than BLEU does.
The test case: Reference: “The account was suspended due to suspicious activity.” Prediction: “The account got blocked because of unusual transactions.” BLEU score: close to zero. Almost no exact n-gram matches. METEOR score: approximately 0.58. It recognized “suspended” and “blocked” as synonyms, “suspicious activity” and “unusual transactions” as semantically close, and the sentence structure as sound.
A human reviewer would score that translation as good. METEOR agrees. BLEU would tell you it failed. For any translation layer that is customer-facing, legally sensitive, or operating across multiple European languages, METEOR is the metric that earns trust with the people who actually read the output.
The QA Split That Most Product Teams Get Wrong
Question-answering sits at the top of the complexity ladder, and it hides a fork that changes everything: are you building extractive QA or generative QA?
Extractive QA pulls a direct span of text from a source document. The model reads the document, finds the answer, and quotes it back. This is the right architecture for compliance tools, regulatory document search, and contract review — anywhere the answer must be traceable to a specific source.
The metric for extractive QA is Exact Match, paired with token-level F1. Exact Match is binary. The model either returned the precise answer string or it did not. Take a CCD2 compliance tool. Document states: “Lenders must disclose the APR in all pre-contractual communications.” Question: “When must APR be disclosed?” Reference answer: “In all pre-contractual communications.” The model returns “In pre-contractual communications” — dropping the word “all.” Exact Match: zero. Token F1: 0.89, giving partial credit for the near-match.
For a compliance context, that dropped “all” could matter legally. Use Exact Match. For a research assistant where partial correctness has value, token F1 is the more forgiving and realistic signal.
Generative QA is different. The model synthesizes an answer from multiple retrieved documents rather than extracting a span. This is the architecture behind most RAG systems — retrieval-augmented generation, which is what powers most enterprise AI assistants being built today. Here you evaluate with ROUGE and BLEU against reference answers, checking both whether key information was included and whether the output is surface-accurate.
The failure mode most teams hit: they start building without deciding which architecture they are using. That ambiguity does not just affect the evaluation dashboard. It shapes what the engineering team optimizes for over the next several months. Pick the architecture, then pick the metric.
The Decision Map

There is a version of every metric that can be gamed. Accuracy ignores class imbalance. BLEU rewards overlap without understanding meaning. Perplexity rewards fluency without checking facts. Every metric has a blind spot, and if you only track one, your model will find it.
The teams that build AI products that actually work in production do three things. They define the task precisely before choosing the metric. They track at least two metrics that check different things — usually one precision-oriented and one recall-oriented. And they treat a good metric score as a necessary condition, not a sufficient one, always pairing it with some form of human evaluation before shipping.
The model is the engine. The metric is the steering wheel. And the steering wheel only works if you installed it before you started driving.